
NFV, Cloud and Middleboxes
In-data-plane recovery
Research papers review and summary
PART 2. Here Link to part 1.
In this post there is a practical step-by-step project with POX SDN, OpenFlow, Click and NFV.
Table of Contents
What about MIDDLEBOXES?
Networks need middleboxes like IDS, Firewalls, Concentrator, Proxy for further packet processing, fact is that interconnecting and manually configuring the routing policies is hard and error prone. An SDN approach could greatly improve the flexibility but does not offer the required L2/L3 methods out-of-the-box.
SIMPLE’s [1] aim is to simplify the policy enforcement for an efficient traffic steering in the network. It faces some challenges like composition, load balancing and packet modifications. Packets in the network need to follow specific middleboxes paths, they can flow in different direction and can raise ambiguous forwarding decisions, also Middleboxes can modify part of packets, making it harder for the SDN to determine the right paths.
This is what SIMPLE addresses with the use of a unified resource management together with a dynamic packet handler which automatically adapts rules to middleboxes packets modifications.
SIMPLE is composed of ResMgr which takes the network as input and outputs a set of of rules, the DynHandler which keeps mappings between packets and a RuleGen which actually generate the configurations. It is important to note that all the operations are resource limited by the amount of CPU, memory and especially switches TCAM flow table size. In fact the optimization decomposition is part of the challenges SIMPLE try to address with an offline pruning stage followed by a more frequent online LP calculation when traffic pattern changes. SIMPLE showed to have very low controller overhead but can gain over 6 times more performances on load balancing compared with today implementations.
Contributions
The aim of the paper is to propose a way to relieve network operators from thinking where to apply policies and instead focusing on what. In fact SIMPLE does not change anything in the middleboxes, it is only allowed to configure the SDN switches.
The basic policy element here is the PolicyChain which is the set of requirements for a specific traffic class that must undergo a specific middleboxes path. Great work is done by the DynHandler to map incoming/outgoing packets using payload similarity and flow correlation techniques (achieving 95% of marching accuracy). This can happen because first few packets of each new flow are sent to the DynHandler for evaluation.
The ambiguous forwarding is greatly solved with the use of SwitchTunnel together with a ProcState and Tag element. Even though these approach are not new, here they are firstly applied to middleboxes. These allow switches to understand in which “state” a packet is and deal with the right forwarding decision (ex: when a packet has to go backwards two or more times to the same switch).
Failures and Policy changes are dealt with the pre-computation of a set of configurations (like a fast-reroute).
Outsourcing Middleboxes to the cloud, any benefits?
In large networks today the number of middleboxes deployed is very high, expensive to manage and brings difficult manual policy management. Middleboxes are used for security reasons like IDS, Firewalls, performance improving like Proxies and caching and finally for reducing bandwidth usage costs with WAN optimizers. Hardware has to be replaced on average every five years and costs can rise very high depending on the network scale, for example for a network of 2850 routers, around 1940 middleboxes have been counted.
The paper shows APLOMB [2], a way of outsourcing such middlebox burden to the cloud along with advantages and disadvantages. Middleboxes are often required some properties like being on-path, choke points and local to an enterprise, but with outsourcing these requirements can be shifted.

APLOMB aims to have the same functional equivalence as traditional deployments, adding no complexity at the enterprise while, most importantly, maintaining an acceptable performance/latency overhead.
Paper shows latency differences between three approaches for relying traffic to Cloud Providers, but the DNS is chosen over the IP redirection because allows flows to be routed towards and from the same CP (Cloud Provider) POP.
Substantially the CP provides the enterprise DNS resolution service and traffic from the Internet immediately reach the CP, and is then tunneled towards the enterprise. One or multiple (for scaling and load balancing) APLOMB gateways are deployed at the enterprise which are the endpoints connecting to the CP.
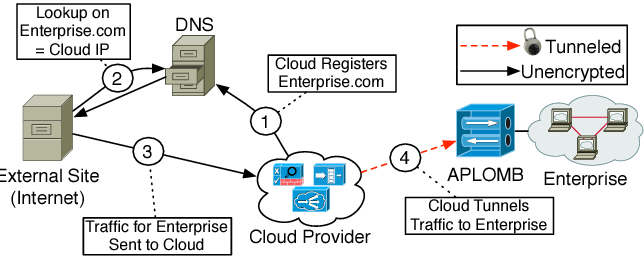
Evaluations have shown that on average 60% of the middleboxes can be outsourced with less than 5ms latency and low bandwidth increase.
Contributions
The paper points out an analysis whether outsourcing the deployment of middleboxes from large networks is feasible, convenient and simple. In fact it provides a study of pros and cons applied to 57 real world deployments along with a complete implementation and evaluation.
The use of CP for middleboxes outsourcing may bring benefits to all sized businesses, because the cost for maintaining and over-provisioning such infrastructure is quite high, especially for small and home offices.
Paper shows different designs of traffic redirection available and evaluate logical correctness and latency of each one, in fact APLOMB chose to use DNS redirection along with compression support in the APLOMB+ gateway for better bandwidth usage.
Smart Redirection is a great feature introduced were to reduce latency, the path is not chosen to be the best from POP to the enterprise, instead it is destination dependent and computed as e2e best latency path from user to POP to the enterprise.
The Cloud controller acts as control plane and has a central role of optimizing redirection strategies, pushing policies to Middleboxes and dynamically scaling capacity in order to meet usage demands.
A Network Function Virtualization Platform
The paper [3] presents Metron, a Network Function Virtualization platform that allows to achieve very high resource utilization in commodity server hardware and very high throughput while inspecting traffic.
It achieves so by offloading part of the computation to the network device, using smart tagging for classifying traffic classes and utilizing those tags for quick hardware dispatching.
Indeed one of the biggest problem is when a packet arrives, how to locate the core responsible for processing it. This would cause costly inter-core communication in the case the wrong core is chosen so packet has to be transferred from a core’s L2/L3 cache to another core’s L2/L3 cache and that is what Metron solves.
Metron allows packet to always stay in the same cache, raising the maximum speed to the cache’s highest one. Packet classification also greatly simplify the load balancing, introducing a quick way to split traffic among different classes or cores, in fact if there is overload the controller (ONOS) can re-balance the traffic classes.
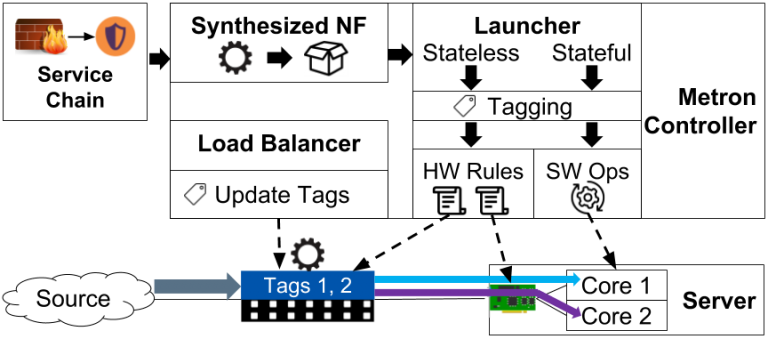
Data Plane follows a master/slave architecture where the master is an agent that interact with HW and the controller, then there is the TAG module with dynamically associates tags to traffic classes to control load distribution and advertise to the controller. As in the Control Plane instead, Metron combines all the pkt processing graphs into a Service Chain with NFs.
In case of failures Metron has always a backup configuration precomputed, stored and replicated to each controller which can apply immediately.
Finally, Metron is able to fully inspect traffic at 40Gbps and 100Gbps with low latency outperforming state of the art current NFV like OpenBox and EC2.
Contributions
A key point in Metron is that it cuts away all the expensive inter-core communication allowing a huge increase in overall performances.
In fact using smart tagging allows to very efficiently dispatch the packets to the right core thus eliminating the need of a dispatcher running on its own thread, this way some important work is relayed to the NIC.
There are way to achieve this like “augmenting the NIC with a software layer” (EC2) or with a series of pipeline each one attributed to one core or with RSS flow hashing but none of these guarantees that the core receiving the packet will also be the one processing it.
This is why for the first time Metron leverages the NIC capabilities, offloading the traffic classification so that packets are tagged as soon as possible. (with SNF)
About the statistic gathering throughout the network, instead of polling each device, adding delay and bandwidth and causing interrupts, Metron uses a smart approach called “power of two random choices” where it actually just asks to two random devices and take the least loaded. These stats along with others from key locations allow Metron to dynamically scale resources, duplicating instances of NFs and splitting flows among them.
Cloud load balancing
The paper [4] proposes ANANTA, a Layer 4 load balancing and NAT software architecture able to satisfy multi tenant cloud requirements scaling-out web services and running on commodity servers.
It has been proposed to achieve that level of reliability, scaling and performance and isolation needed in today cloud’s datacenter. Essentially Ananta divides the load balancer into a decentralized horizontally scalable data plane and a consensus-based reliable control plane.
This architecture has been used by Microsoft Azure cloud with success achieving more than 100Gbps throughput for a single IP and an aggregated one reaching 1Tbps.
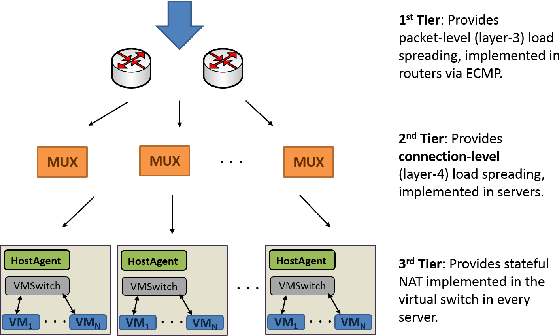
There are three tiers in the data plane: first the packet arrives at routers, here via ECMP (L3) load is randomly distributed to MUX devices, second MUX provide a connection-level (L4) load balancing spreading load to the servers, third the virtual switch in each server provide stateful NAT.
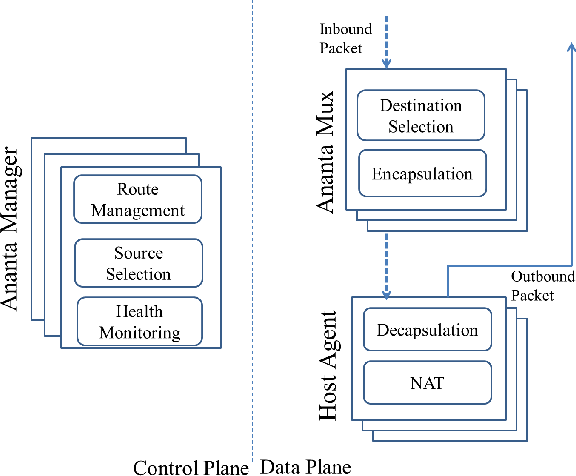
There is a controller Ananta Manager (AM), one or more Multiplexer (MUX) and the Host Agent (HA) in each server. Each server has assigned a private Direct IP (DIP) and each service a Public Virtual IP (VIP).
The Manager is critical for configuring Host Agents and MUXs but also because provides port allocation for outbound SNAT to the Host Agent. The MUX is a BGP speaker which advertise itself to the Manager for routes towards its DIPs. And the Host Agent manages DSR and NAT along with FastPath and VM health monitoring.
Contributions
The paper identifies the most important requirements and overcome them introducing Ananta, being able to provide cloud-scale solution for load balancing.
A key difference from Ananta and other load balancer systems is that here Data/Control plane processing is in part offloaded to the end systems relieving the network from load and more difficult state management.
Ananta makes use of Direct Server Return or DSR to relieve Load balancers (MUX) from the useless work of processing the packets back to destination. Indeed the packet leaves the Host Agent with the destination IP already set so that it can reach the client without passing through the MUX.
Furthermore using a Virtual IP allows easy enforcement and management of ACL lists and make it easier to handle disaster recovery or upgrades since it can be dynamically mapped to another instance. Ananta makes use of BGP between Manager and MUXs which allows automatic failure detection and recovery.
Importantly, the network scales as it increases because much work is done by hosts and MUX are horizontally scalable.
Connectivity recovery directly in the Data-Plane
The paper [5] proposes BLINK a completely new approach for dealing with network failures.
It recovers from failures leveraging TCP signals directly within the data plane with no expensive calls to the control plane. It does take advantage from the key intuition that TCP flows experience a predictable behavior in case of disruption (retransmission).
BLINK first selects TCP flows to track (limited amount due to memory constraints) then detect major disruptions (if majority of flows experience retransmission) and in the end recover connectivity (mainly applying backup path) all in the data plane.
BLINK is able to recover in sub-second through fast rerouting and quick activation of backup path and is thus able to solve problem of the long convergence time for remote failures (frequent and slow to repair) which used to invoke the control plane to let the topology converge (BGP updates).
Challenges to achieve this are multiple and between them we see memory constraints (sampling), rerouting must apply only on major disruptions and must ignore temporary or casual retransmissions (noisy signals) and the impossibility to know the root cause of those failures (forwarding correctness).
BLINK is implemented in Python and tested on a Tofino hardware switch and provide a good balance between detection and robustness to noisy signals offering on the average a fast sub-second recover. Importantly BLINK is able to be insensitive to normal congestion events.
Contributions
The paper exposes a completely new approach to recover from failures directly in the data plane leveraging TCP signaling. In fact it introduces a new framework for fast rerouting (sub-seconds) for both local and remote failures.
BLINK avoids memory problems with a Flow selector which keeps track of the 64 most active flows evicting the non active, and also the active ones after a certain amount of time.
Blink importantly allows to quickly recover from loops and blackholes by checking connectivity of each backup path before and after being applied.
Blinks leverage TCP congestion knowledge about RTO to set the right timer (default 2 sec) for flows eviction and avoid noisy signals causing useless temporary re-routing.
BLINK make use of a logic pipeline for processing the various stages which are Selection, Detection and ReRouting.
Here link to PART 1
References
- [1]Z. A. Qazi, C.-C. Tu, L. Chiang, R. Miao, V. Sekar, and M. Yu, “SIMPLE-fying Middlebox Policy Enforcement Using SDN,” in Proceedings of the ACM SIGCOMM 2013 Conference on SIGCOMM, New York, NY, USA, 2013, pp. 27–38, doi: 10.1145/2486001.2486022 [Online]. Available at: http://doi.acm.org/10.1145/2486001.2486022
- [2]J. Sherry, S. Hasan, C. Scott, A. Krishnamurthy, S. Ratnasamy, and V. Sekar, “Making Middleboxes Someone else’s Problem: Network Processing As a Cloud Service,” in Proceedings of the ACM SIGCOMM 2012 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication, New York, NY, USA, 2012, pp. 13–24, doi: 10.1145/2342356.2342359 [Online]. Available at: http://doi.acm.org/10.1145/2342356.2342359
- [3]G. P. Katsikas, T. Barbette, D. Kostić, R. Steinert, and G. Q. M. Jr., “Metron: NFV Service Chains at the True Speed of the Underlying Hardware,” in 15th USENIX Symposium on Networked Systems Design and Implementation (NSDI 18), Renton, WA, 2018, pp. 171–186 [Online]. Available at: https://www.usenix.org/conference/nsdi18/presentation/katsikas
- [4]P. Patel et al., “Ananta: Cloud Scale Load Balancing,” ACM SIGCOMM Computer Communication Review, vol. 43, Aug. 2013, doi: 10.1145/2486001.2486026.
- [5]T. Holterbach, E. C. Molero, M. Apostolaki, A. Dainotti, S. Vissicchio, and L. Vanbever, “Blink: Fast Connectivity Recovery Entirely in the Data Plane,” in 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI 19), Boston, MA, 2019, pp. 161–176 [Online]. Available at: https://www.usenix.org/conference/nsdi19/presentation/holterbach